
You can also read it on Towards Data Science.
In this tutorial, I’m going to show you a few different options you may use for sentence tokenization. I’m going to use one of my favourite TV show’s data: Seinfeld Chronicles (Don’t worry, I won’t give you any spoilers :) We will be using the very first dialogues from S1E1). It’s publicly available on Kaggle platform. scripts.csv has dialogue column that has many sentences in most of the rows and we’re going to split it into sentences.
The steps we will follow are:
- Read CSV using Pandas and acquire the first value for step 2.
- Sentence Tokenization
- Tokenize an example text using Python’s
split(). (Never use it for production!) - Tokenize an example text using regex.
- Tokenize an example text using spaCy.
- Tokenize an example text using nltk.
- Tokenize whole data in
dialoguecolumn using spaCy. - Split list of sentences to a sentence in each row by replicating rows. Check the modified DataFrame and save to your disk.
Note: Many of the gists don’t show all the outcomes if you look only in the article. Please don’t forget to check them on GitHub.
Note-2: Many of the gists won’t work if you don’t follow the steps in the article in order. You might check the last gist in the conclusion section or you might go step-by-step.
READ CSV
I’ll keep this very short. Put scripts.csv to the same directory with your Python script or Jupyter notebook and then run the following commands:
give the path of CSV file to FILE_PATH variable
You can directly give scripts.csv to Pandas’s read_csv() but it is always more robust to use os or glob to give file path. It’s also a good practice for production. You might forget to change all of magic filenames if you use strings.
Let’s create a DataFrame from our CSV file and assign the first row’s Dialogue column to first_dialogue variable.
we will use “first_dialogue” in sentence tokenization section
So, we are ready to try different sentence tokenizers. This might be a great example because it has many punctuations such as three dots, exclamation mark, question mark; long sentences; sentences without punctuation between them; etc.
Sentence Tokenization
1. Tokenize an example text using Python’s split()
This will be a naive method, which you should never use for sentence tokenization! I prefer using built-in functions as much as possible in my projects. But if it doesn’t fit, then don’t use it, check for the alternatives (you will probably find a better library because Python has a vast community and lots of great open-source libraries!). So, you might use the following gist, which will only work if you are very lucky and all of your sentences end with “.”:
**
Not so good, right? I see that split() is used in many articles for word tokenization. Which might be acceptable because it splits texts by taking care of extra spaces, etc. For sentence tokenization, it just doesn’t work. You might use replace()and then split() to replace all end-of-line characters with one character and split the text into sentences using that character. It would give a better result, but the performance of your code would decrease.
Another problem is we’re losing the character we used for splitting. If we aggregated the transformed data, we wouldn’t have the original punctuations any more.
2. Tokenize an example text using regex
Regular expression is always useful if you’re working on texts. It’s a quite old and robust approach. Many programming languages offer it natively. So, you can use your regex across different languages with small or no changes.
Let’s give it a try to one of the accepted answers on Stackoverflow (with a small change, by adding |! to the third group):
**
Let me explain the regex pattern: (?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=\.|\?|!)\s step by step:
(?<!X)Yis called negative lookbehind. It tries to capture Y (any whitespace character\sin our case) where preceded characters of Y do not match with X. For example, let’s say you have this regex:(?<!TEST)MATCH. If your text is “TESTMATCH”, it will not match, if it’s “RANDOM_MATCH” (preceded characters are not “TEST”), it will match.
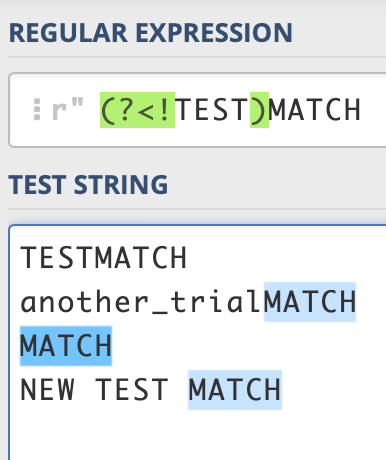
As you may see, all “MATCH” values are matched but the first row because it has “TEST” as preceded characters
(?<=X)Yis called positive lookbehind. It tries to capture Y (any whitespace character\sin our case) where preceded characters of Y match with X. Let’s use the same example as above and check the outcomes:
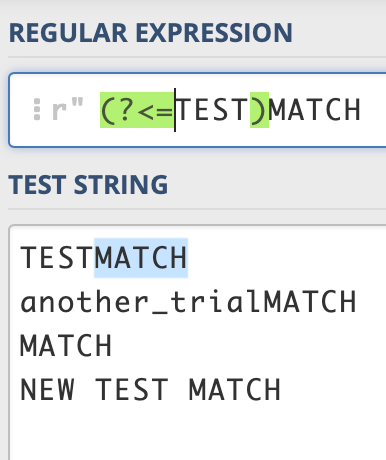
This time only the first row is captured because the rest of the rows don’t have “TEST” as preceded characters
In our regex, we have three capturing groups: the first two are looking for negative lookbehind and the last one is looking for a positive lookbehind. Now, let’s look at the inside of these capturing groups to understand what kind of strings we’re looking for:
- Inside of the first capturing group is as follows:
\w\.\w..\wmatches any word character (letter, number, or underscore).\.matches literal dot character (backslash is the escape character in regex)..matches any character. An example match:i.e. MATCH - Inside of the second capturing group is
[A-Z][a-z]\.. It matches any lowercase or uppercase letter following with dot character. An example match:Mr. MATCH. - Inside of the third capturing group is
\.|\?|!. We already know that\is used for literal characters.|means to match either the first part or the latter part. In other words,(A|B|C)means either match A, B or C. In our case, it will match either dot, question, or exclamation mark.
We may finally know all we need to know about our regex. To sum up, we’re searching for whitespace characters by checking its preceded characters. If it passes from our three validations, we match it. So, we can split the text from these matches.
The disadvantage of using regex is:
- It might be quite painful to explain what is going on! It’s not intuitive. You should spend some time to learn it, otherwise, it will look scary.
- You might create infinite loops or low-performance regular expressions if you’re not much familiar with it.
- It’s not easy to cover edge cases before you face with them. When you start to write a regex, you might easily miss some of these cases.
- Our regex relies on whitespace characters. If there is no whitespace between two sentences, then it doesn’t match anything. So, it might fail if your text is not properly formatted. For example, if you give this text to our regex, “This is an example sentence.This is another one without space after the dot.”, it will think it’s one sentence.
The advantage of using regex is:
- You don’t need to rely on third-party libraries.
- It’s lightning fast because just as many of Python’s built-in functions,
remodule is converted and executed on C. - It exists since the 1950s, and it’s a quite known thing for string search, replace, etc. You can write one regex in Python and use it in Javascript with minor changes. You only need to know the programming language specific behaviours, the rest will be easy. But, you can’t use a Python library in Javascript. If you can, you will need a workaround, or you will use a Python API etc.
3. Tokenize an example text using spaCy
spaCy is capable of preprocessing texts in many languages. It offers tokenization, lemmatization, linguistic features, creating pipelines, training, running on GPU, etc. So, it’s a resourceful and powerful library. If you have unstructured text data such as scraped texts from the web, I’d suggest using it without any hesitation. If you think of only doing basic preprocessing, it might add extra complexity which you don’t actually need.
Before you try spaCy’s tokenization, you should download the library and one of its models. We will use the small English model which will be sufficient for our task.
Download library and language model, then tokenize first_dialogue
This approach takes a long time. However, this is a bit misleading because spaCy might work much faster. It took a long time because we need to convert each value to an nlp object and we used the default sentence segmentation component. It is called DependencyParser. It’s possible to modify -to remove dependency parser and use custom segmentation- nlp()object and define it without using any model. Let’s use sentencizer pipeline component this time:
**
As you can see, there is a trade-off between the speed and the result. sentencizer struggled just as nltk and regex because it uses a rule-based strategy.
The advantage of using spaCy is:
- It is a well-documented library which is maintained actively by a large community.
- It offers tons of NLP functionalities that you might use.
- It supports many languages such as German, Dutch, French, and Chinese.
The disadvantage of using spaCy is:
- It’s slower than
remodule in normal usage. - It might be overkill to include it to your project and use it only for tokenization.
4. Tokenize an example text using nltk
nltk is another NLP library which you may use for text processing. It is natively supporting sentence tokenization as spaCy. To use its sent_tokenize function, you should download punkt (default sentence tokenizer).
**
nltk tokenizer gave almost the same result with regex. It struggled and couldn’t split many sentences.
When we check the results carefully, we see that spaCy with the dependency parse outperforms others in sentence tokenization. It is handling the case which two sentences do not have whitespace character between them. It also handles if there are two sentences and there is only a space between them. Thus, it gave the best result.
I’m going to benchmark when I apply these tokenizations to all data. We will also see their speed. I’m going to skip split() for benchmarking. It is so obvious that we can’t consider to use it.
Transform whole data
We will create lambda functions and use Pandas DataFrame’s apply method. Before transforming the whole data, I’d like to test the performances using the first 5000 rows. The outcomes are as follows:
**
As you can see, regex is blazingly fast. It’s 10x faster than nltk and spaCy with sentencizer! It’s ~1600x faster than spaCy with the dependency parse. Yet, you might try to increase spaCy’s speed more. You may use nlp.pipe which helps to send column values in a batch instead of one-by-one. You might also modify your code to run spaCy transformation using multiprocessing. However, I’m not going to show it here. You can check the link in the further reading section.
I’m going to use the first approach we have used in spaCy to transform whole data:
nlp = spacy.load("en_core_web_sm")
df["Dialogue"] = df["Dialogue"].apply(lambda x: [sent.text for sent in nlp(x).sents])Transform list of sentences to one sentence in each row
We have transformed data, which have a list of sentences in each Dialogue column. And it may not useful for further analysis. Luckily, Pandas offers an elegant method which will help us to create new rows for each sentence in the lists. We will replicate the values in other columns, but our Dialogue column will have only one sentence in a row. And, its type will be string, not list.
**
Okay, that’s it! In the first cell, we called explode() method with ignore_index parameter, it will create a new index for each row but it will keep the previous index values in another column named Unnamed 0 . In the second cell, the new index and the previous index values are renamed to Sentence ID and Dialogue ID respectively. It is important to keep the track of your original data and allow yourself to transform backwardly. Because you may make amazing analysis in the sentence level, after you’re done you may want to see the results in the dialogue level. It might sound silly for this task but it might be useful in other text corpora. In our case, we can use Dialogue ID if we would like to return to original data because we’re 100% sure that it has unique IDs for each dialogue. A simple group_by() with correct aggregation parameters (taking first values for existing columns, and taking sum/mean etc. for the new columns that we add for analysis) would give use the original version.
We have come up to the last point. Let’s save our file, and complete our tutorial:
df.to_csv("scripts_tokenized.csv")Conclusions
In this tutorial, I have tried to show you a few different approaches to sentence tokenization. These approaches are not the only approaches we have currently. NLP is quite a big subject and I’m sure you may find alternatives. I tried to select the prevalent libraries.
If you think of further text preprocessing, I would certainly suggest using spaCy. Because it is easy-to-use, documentations are richly detailed, its community has almost 500 members, and new features are constantly coming.
If you think of tokenizing your text only, I would reformat the text a bit, and then would use regex, so that importing Python’s re module to my script would be enough instead of adding new dependencies.
Full working code in one gist:
**
Thanks for reading up to the end!
Further Reading
- Multiprocessing on spaCy: https://prrao87.github.io/blog/spacy/nlp/performance/2020/05/02/spacy-multiprocess.html#Option-1:-Sequentially-process-DataFrame-column
Resources
- Sentence Segmentation — SpaCy: https://spacy.io/usage/linguistic-features#sbd-component
- Punk sentence tokenizer: https://www.nltk.org/_modules/nltk/tokenize/punkt.html
- Regex sentence tokenizer: https://stackoverflow.com/a/25736082/9686506
- Regex cheatsheet: https://www.rexegg.com/regex-disambiguation.html
- Pandas explode(): https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.explode.html
